ROOFLINEとNXP、EIQ NEUTRON NPUにおけるLLM向けの次世代ソフトウェア・サポートを実現
高度なAIモデルは急速にエッジ・デバイスへと移行しており、CPUやGPUだけでは対応しきれないデバイス内での演算処理への需要が高まっています。この需要に応えるため、専用のAIアクセラレータであるNPUがエッジSoCに組み込まれつつあります。
NXP® Semiconductorsとの協業により、Rooflineの拡張性の高いMLIRおよびIREEコンパイラ・インフラストラクチャを活用し、当社のヘテロジニアス実行スタックをNPUへと拡張しました。本ケーススタディでは、i.MX 95アプリケーション・プロセッサ上のNXP製eIQ® Neutron NPUにおけるLLM対応を起点として、このソフトウェア・ソリューションがもたらす3つの主な利点、すなわち1) 幅広いモデルの対応、2) 2GBを超えるモデルにおけるアクセラレータのメモリ制限の克服、3) CPUのみでの実行と比較して最大3.2倍のLLM性能向上を実現したことを紹介します。
ソフトウェアの進化が、エッジAIハードウェアのイノベーションの真の可能性を引き出す
エッジAIの分野では、新しいモデルやユースケースが急速に登場する一方で、半導体メーカは、ますます高性能なNPUを搭載したプロセッサを市場に投入しています。しかし、ハードウェアの革新だけでは、実世界での普及にはつながりません。決定的な要因は、アプリケーションとシリコンの連携にあります。この連携を左右するのが「ソフトウェアの進化速度」です。それは以下の2つの重要な要素に支えられています:
1. 導入直後のサポート:新しいモデルは、デフォルトのままターゲット・ハードウェア上でコンパイルおよび実行可能です。すべてのモデルにおいてパフォーマンスが完全に最適化されているわけではありませんが、これにより、即時の評価、プロトタイピング、および製品開発が可能になります。
2. 短期間で性能を引き上げられる最適化曲線:コンパイラのターゲットを絞った改良により、手動によるカーネル・エンジニアリングに数ヶ月を要するのではなく、数日または数週間で、機能レベルから実運用可能なレベルまでパフォーマンスを向上させることができます。
このソフトウェアによる環境整備により、アプリケーションおよび製品開発者は、自社の真の差別化要因である「ユースケースの洗練と反復、機能の向上、市場投入までの期間の短縮」に注力できるようになります。
RooflineのコンパイラインフラストラクチャとNXPのハードウェア固有の専門知識が融合し、NPUの「Day-0」サポートを実現
NPUにおけるソフトウェア開発のスピードアップを実現するには、柔軟かつ効率的なAIコンパイラ・インフラストラクチャと、ハードウェア固有の高度な最適化ノウハウという、互いに補完し合う2つの能力が必要です。MLIRとIREEを基盤として、Rooflineはハードウェア非依存の要素とハードウェア固有の要素を明確に分離するソフトウェア・インフラストラクチャを提供します。この強力なエコシステムを基盤として、Rooflineのインフラストラクチャはフレームワーク間のシームレスなモデルのインポートを可能にし、汎用的な最適化を適用するとともに、ヘテロジニアス実行のようなターゲット非依存の機能を提供します。
ハードウェア固有の側面では、NXPが自社シリコン向けのソフトウェア最適化における深い専門知識を提供します。バックエンドは特定のアーキテクチャ向けに専用に設計され、継続的に最適化されるため、演算が最大の効率で実行されることが保証されます。この関心の分離により、多様なハードウェア・ポートフォリオ全体でDay-0サポートを実現するスケーラブルなソフトウェア・スタックが可能になります。新しいデバイスをターゲットにする場合、新しいハードウェア固有のバックエンドを統合する必要はありますが、スタック全体を根本から書き直す必要はありません。
RooflineとNXPのコラボレーションの第一歩として、私たちはこのインフラストラクチャをi.MX 95 SoCに適用し、最初のアクセラレータ・バックエンドとしてeIQ Neutron NPUをターゲットとしました。
NXPのeIQ Neutron NPUは、MAC演算を多用するAIワークロードに優れている:ビジョンネットワークには最適だが、LLMの実装には課題あり
NXPはAI機能を大幅に拡充しています。この拡張されたエッジAI実現における重要な基盤となるのが、高度にスケーラブルなアクセラレータ・コア・アーキテクチャであるeIQ® Neutronニューラルプロセッシングユニット(NPU)です。NXP i.MX 95 SoCにおいて、eIQ Neutron NPUは、専用の2GBメモリ領域を備えた8 eTOPSのアクセラレータとして実装されていて、eIQ Neutron NPUは、乗算積和(MAC)演算を大規模に実行するために専用に設計されています。行列乗算、畳み込み、内積はすべてMACに還元され、密結合されたローカル・メモリを備えたニアメモリ・コンピューティング・アーキテクチャに数千のMACユニットを集約することで、Neutronは高い演算利用率とエネルギー効率を実現します。標準化されたビジョン・ベンチマークにおいて、このデザインはその能力をすでに実証しています。NXPの報告によると、同等のTOPSおよびメモリ・リソースにおいて、競合する組み込みNPUと比較して平均1.8倍の高速化を達成しています(1)。
このアーキテクチャは、畳み込み演算や行列演算を多用するビジョン・ワークロードには最適である一方、LLM推論への適用にはいくつかの課題があります。NXPのeIQ Neutron NPUは整数演算のみを実行するため、このアクセラレータ上で実行できるのは量子化された演算に限られます。LLMは、Neutronに最適化されたMAC(乗算・積算)を多用する行列乗算と、完全に量子化されたモデルであっても浮動小数点演算を必要とする演算を組み合わせています。さらに、高性能なエッジLLMは、NXP eIQ Neutron NPUの2GBのローカル・メモリ容量を超える可能性があります。
したがって、LLM向けにNXP eIQ Neutron NPUの性能を最大限に引き出すには、ヘテロジニアス実行が不可欠です。つまり、MAC演算を多用する行列乗算をNPUにオフロードし、残りの演算をCPUで実行するとともに、効率的なスケジューリングとメモリ管理を通じてこれらを連携させる必要があります。このワークロードの分割により、モデルの機能を完全に維持しつつ、アクセラレータを高効率で動作させることが可能になります。
NXPとRooflineが提携し、Neutron NPUのソフトウェア・サポートを強化
RooflineとNXPは共同で、NXPのi.MX 95 SoC上のNXP eIQ Neutron NPUとCPUを異種混在環境で動作させるコンパイル済みLLM推論を実現しました。これは、以下の3つの具体的な取り組みを通じて達成されました:
1. バックエンド統合:RooflineとNXPは共同で、Neutronのバックエンドを、MLIRおよびIREEを基盤とするRooflineのコンパイラインフラストラクチャに統合しました。コンパイラはモデル内の行列乗算を自動的に識別し、それらをNeutronにルーティングする一方、残りのすべての演算はCPU向けにコンパイルされます。
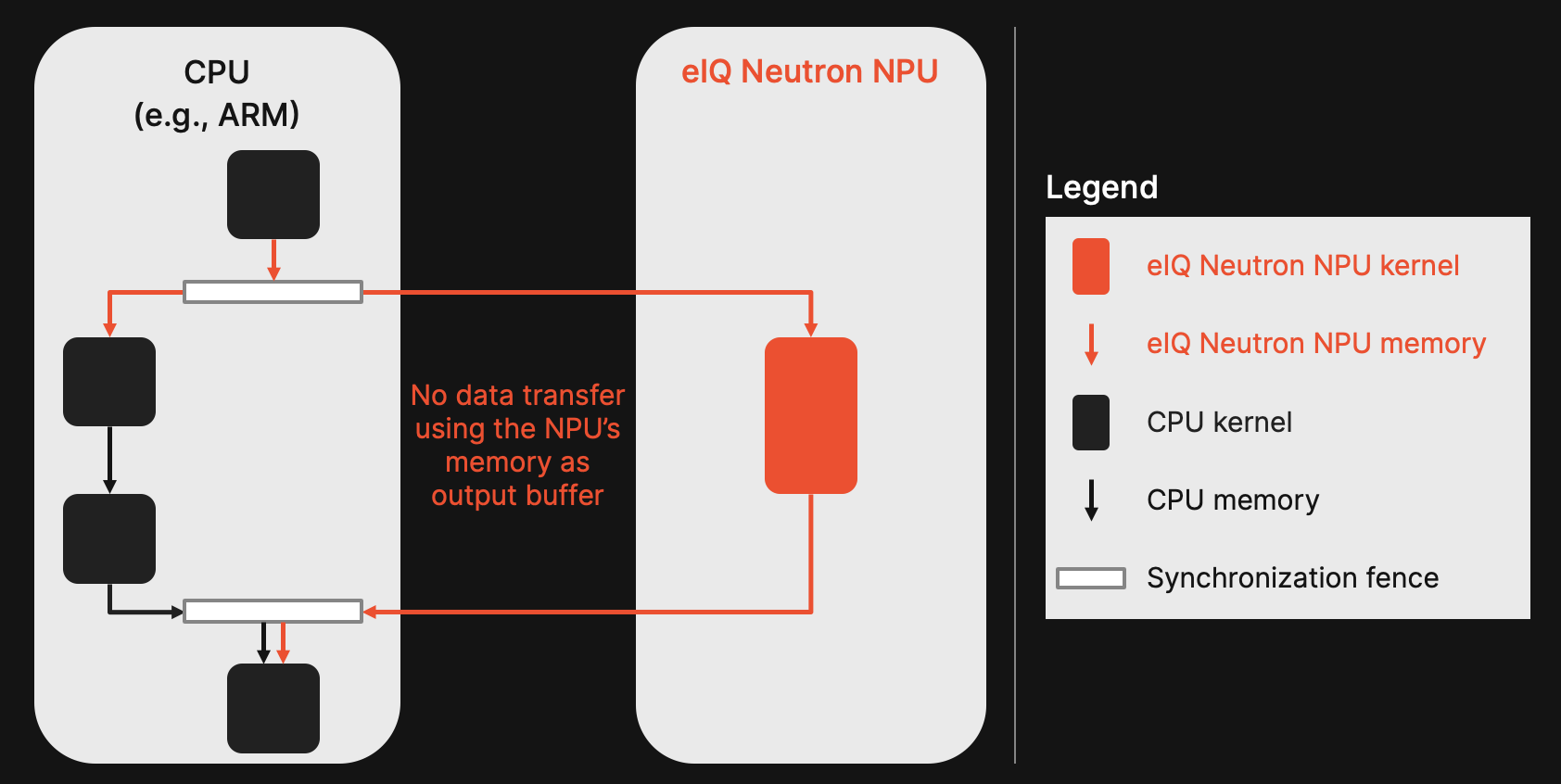
2. 非同期ヘテロジニアス実行:以前のヘテロジニアス実行に関するケーススタディおよび図1に基づき、CPUとNPU間の非同期実行を実現しました。アイドル時間を招くブロック型呼び出しの代わりに、軽量な同期フェンスを通じて実行を調整します。これにより、各デバイスはアイドル時間を最小限に抑えつつ、最も得意とする演算を実行できるようになります。
3. NPUの共有メモリ:Neutronには、CPUとNPUの両方からアクセス可能な共有メモリ領域があります。これにより、両方の処理ユニットが同じメモリから読み書きを行うことが可能になります。私たちはこれを活用し、NXP eIQ Neutron NPUのメモリ領域に必要な入力および出力バッファのみを割り当てることで、デバイス間のデータ転送オーバーヘッドを最小限に抑えました。CPUは、先行する演算の結果をNPUの入力バッファに直接書き込み、後続の演算のための入力をNPUの出力バッファから直接読み取ります。これにより、冗長なコピーが排除され、アクティブなI/OバッファのみがNPU上に存在するため、2GBのメモリ制限を超えるモデルの展開が可能になります。
シームレスな非同期実行により、最新のトランスフォーマー型LLMをCPUとNPU上で同時に実行できるようになりました。以下の動画では、Qwen3-1.7Bを例にその様子をご覧いただけます。
NXP eIQ Neutron NPU における LLM 導入の明確な利点
Roofline と NXP による NXP の eIQ Neutron NPU への共同対応により、3 つの重要な成果がもたらされました。これらはすべて、NXP ハードウェア上で開発を行う開発者にとって、直接的な実用上のメリットをもたらします。
1. NXP の eIQ Neutron NPU 向け完全コンパイル型 LLM 対応: 上記の動画で紹介された初期実装を起点に、RooflineとNXPはわずか数週間で、ONNXおよびPyTorch由来の10種類以上のLLMからなる共同モデル・ズーで検証された、事実上あらゆる8ビット量子化LLMへのソフトウェア・サポートを拡張しました。コンパイラレベルでのMatmulオフロードはあらゆるLLMアーキテクチャで機能し、真にコンパイラベースのスタックだけが提供できるスケーラビリティを実証しています。これが「関心の分離」がもたらす直接的な成果です。新しいモデルも、モデル固有のエンジニアリングを必要とせずにNeutron上でコンパイルおよび実行可能です。
2. 大規模モデルへの対応:NPUの共有メモリとゼロコピーアプローチにより、Qwen3-1.7B(2GBをわずかに上回る)やGemma-2-2b-it(約3.5GB)など、NPUの2GBメモリを超えるモデルも利用可能になります。
3. 明確なパフォーマンス向上:検証済みの全モデルにおいて、matmul演算をNeutronにオフロードすることで、LLMのプリフィルフェーズ中に一貫した速度向上が得られます。図2は、さまざまなサイズの6つのモデルに関するベンチマーク結果を示しています。この速度向上により、i.MX 95 SoCの全コアを利用する6コアCPUのベースラインと比較して、最大1.9倍のパフォーマンス向上が実現します。

これらの結果は、NXPのハードウェア上で開発を行う開発者にとって、以下の3つの実用的な意味を持ちます。
1. NXPのeIQ Neutron NPUにおけるDay-0 LLMサポートにより、市場投入までの時間を短縮。
2. これまで利用できなかった大規模なモデルを導入することで、新たなユースケースを実現。
3. パフォーマンスの向上を活用し、推論時間を短縮するか、同じSoC上で実行される他のワークロードのために演算リソースを解放できる。図3に示すように、単一のCPUコアと比較した場合、NPU + CPUでは最大3.2倍の性能向上が確認されています。

初期LLM対応からSOC全体のフル活用まで
このケーススタディでは、スケーラブルなコンパイラ・インフラストラクチャが、NPUベースのエッジSoCのソフトウェア開発スピードをいかに向上させるかを示しています。Day-0からのモデルサポートと急勾配の最適化曲線により、NXPハードウェアを利用する製品およびアプリケーション開発者は、最も重要なこと、すなわち、他社との差別化を図るアプリケーション、ユーザー・エクスペリエンス、製品の独自性の構築に注力できるようになります。
次に、トークン生成時のSoC利用効率を確保するため、NXP eIQ Neutron NPUの対応範囲をLLMのプリフィル段階からデコード段階へと拡張します。また、NXP eIQ Neutron NPUのオフロード機能をさらなる演算子タイプに拡張し、従来のCNNのような行列乗算負荷の低いモデルにおいてもパフォーマンス向上を実現します。その目的は、あらゆるユースケース向けのAIモデルがNXP i.MX 95 SoC全体で実行可能となり、CPU、GPU、NPUを最適に活用できるようにすることです。
参考文献
(1) Bamberg, Lennart, et al. "eIQ Neutron: Redefining edge-AI inference with integrated npu and compiler innovations." arXiv preprint arXiv:2509.14388 (2025)

