Dynamic shape support: A key enabler for on-device LLM inference
LLMs are moving onto edge devices, but efficient on-device execution remains difficult. Unlike traditional AI inference, where inputs have fixed dimensions, such as a camera frame of constant resolution, LLMs must handle user prompts of unpredictable length. This variability produces so-called dynamic shapes: tensor dimensions that cannot be determined ahead of time. LLM deployment at the edge is specifically challenging because the hardware typically demands fixed-size computations for efficiency, which LLMs do not provide.
This case study shows how Roofline achieves up to 23× higher throughput by solving one of the most fundamental bottlenecks in efficient on-device language model inference: dynamic shapes in the prefill stage.
LLMs are moving to the edge, but dynamic prefill is breaking traditional inference assumptions
LLM deployment is moving to the edge rapidly, driven by two main trends:
1. Language models are shrinking in size, making it feasible to run more functionality directly on device.
2. Edge hardware is becoming powerful enough to run meaningful generative AI workloads locally.
This shift towards the edge is enabling new use cases such as multi-modal robotic systems or industrial agentic assistants leveraging image-to-text models, as we have showcased in this news blog.
While the use of LLM inference has matured in server and cloud environments, deploying similar models efficiently on edge devices remains challenging due to three key reasons. First, modern edge chips increasingly rely on GPUs and NPUs with instruction sets that have fixed SIMD vector or tensor widths, so peak performance depends on input shapes that align well with these fixed widths. Second, the cloud benefits from relatively uniform hardware, which makes it practical to cover most performance-critical operations with hand-written, highly optimized kernels; this approach does not scale to the edge, where hardware is far more diverse. Third, cloud inference can often adapt to shapes at runtime through JIT (just-in-time) specialization, while edge inference usually requires AOT (ahead-of-time) deployment, so the compiled artifact must handle dynamic prompt shapes efficiently without recompilation.
LLM inference is fundamentally different from traditional one-shot inference, adding another layer of complexity for edge deployment. Instead of a single static forward pass, LLMs execute iteratively and split into two phases: 1) the prefill phase and 2) the decoding phase. During the prefill phase, the model first processes the user prompt, for example the input tokens “Quantization can” in Figure 1. The model then enters the decoding phase, where it generates the continuation token by token across multiple iterations, producing outputs such as “be”, “used”, “to”, and “save” step by step.

The prefill stage introduces one of the toughest edge deployment challenges: dynamic shapes. Prompt lengths are a user input during runtime and thus vary unpredictably in length. This forces compilers to handle tensor dimensions that cannot be fixed ahead of time. While CPUs can often accommodate this flexibility with low-level techniques such as padding, peeling or masking, the problem becomes far more critical on edge accelerators such as GPUs with Tensor Cores or NPUs optimized for specific operator patterns, where peak throughput depends on fixed tensor shapes.
The underlying compilation problem
In the prefill stage, the input size of the prompt is unpredictable at runtime as it depends on the user input. At the same time, hardware instructions remain static. As an example, a device may be optimized for fixed 16×16 tensor instructions, while the actual prompt requires multiplying a 30×16 input. This creates a mismatch between the dynamic input and the fixed hardware instructions.
Dynamic shapes are not a problem for correctness, since compilers can always generate general code that runs for arbitrary prompt lengths. The challenge is achieving high performance, because modern accelerators reach peak throughput only with fixed-size vector or tensor instructions.
In practice, dynamic shapes can be addressed at two abstraction levels: Local, per-operator techniques and global, model-level constraints.
Dynamic shape handling at operator-level
On CPUs, it is often sufficient to handle them locally inside each operation through low-level techniques such as padding, peeling, or masking. Here is a high-level overview of the most relevant per-operation techniques:
1. Padding: Extends the input to a fixed size in each operation. This is easy to apply but can trigger extra kernel launches, allocations and memory transfers. See the current IREE implementation.
2. Peeling: Splits the computation over a dynamic dimension into a fixed-width vectorized part plus a smaller remainder part. This works well on CPUs, where loops can be efficiently divided this way, but it does not generalize well to GPUs and accelerators with fixed SIMD or tensor instruction widths. See the current IREE implementation.
3. Masking: Executes fixed-size computation while masking out unused elements. Supported on some hardware but often wastes work and incurs performance penalties.
However, these operation-level fixes do not generalize well to GPUs and NPUs. These accelerators achieve peak performance only when the entire computation is planned around fixed, hardware-friendly tile sizes. If input shapes do not match these assumptions, no amount of local padding, masking, or peeling inside individual operations can recover the lost performance.
Roofline introduces constrained input shapes for GPUs and NPUs
Roofline expands these operator-level techniques with methods to address dynamic shapes already at a higher abstraction level in the compiler. By introducing dynamic-shape-aware infrastructure into its compiler stack, Roofline enables GPUs and other fixed-instruction devices to execute the prefill stage efficiently despite unpredictable prompt lengths. Instead of applying costly fixes inside each operation, Roofline constrains variability once at the model boundary through a single global guarantee on the prompt shape.
The core idea is to restrict dynamic prompt lengths to hardware-friendly multiples. Prompt tokens are padded only once at the model input to hardware-friendly multiples such as 32, establishing a global divisibility guarantee that applies across the entire computation. This allows every downstream operation to select efficient fixed-size tensor instructions, which is essential for fully utilizing GPU Tensor Cores and NPUs.
By shifting dynamic shape handling from repeated operation-level complexity to a single input-level constraint, Roofline makes prefill execution practical and efficient for edge LLM deployment on GPUs and NPUs.
Adding this feature to the existing set of operator-level techniques allows to choose the right approach for dynamic shape handling depending on the respective target hardware.
Constrained dynamic shapes deliver up to 23× higher prefill throughput
Roofline turns the dynamic prefill stage from a deployment bottleneck into an optimizable workload. By constraining dynamic shapes at the input level, Roofline achieves major throughput gains for GPUs and NPUs. For our benchmarking experiments, we have run a Qwen3-0.6b on an NVIDIA RTX 3070 GPU and found that
1. Operation-level padding alone improves prefill performance by roughly 3× compared to the baseline without any dynamic shape optimizations.
2. Input-level padding plus constrained dynamic input shapes increase throughput by more than 23× compared to the baseline. Check out the current IREE implementation.
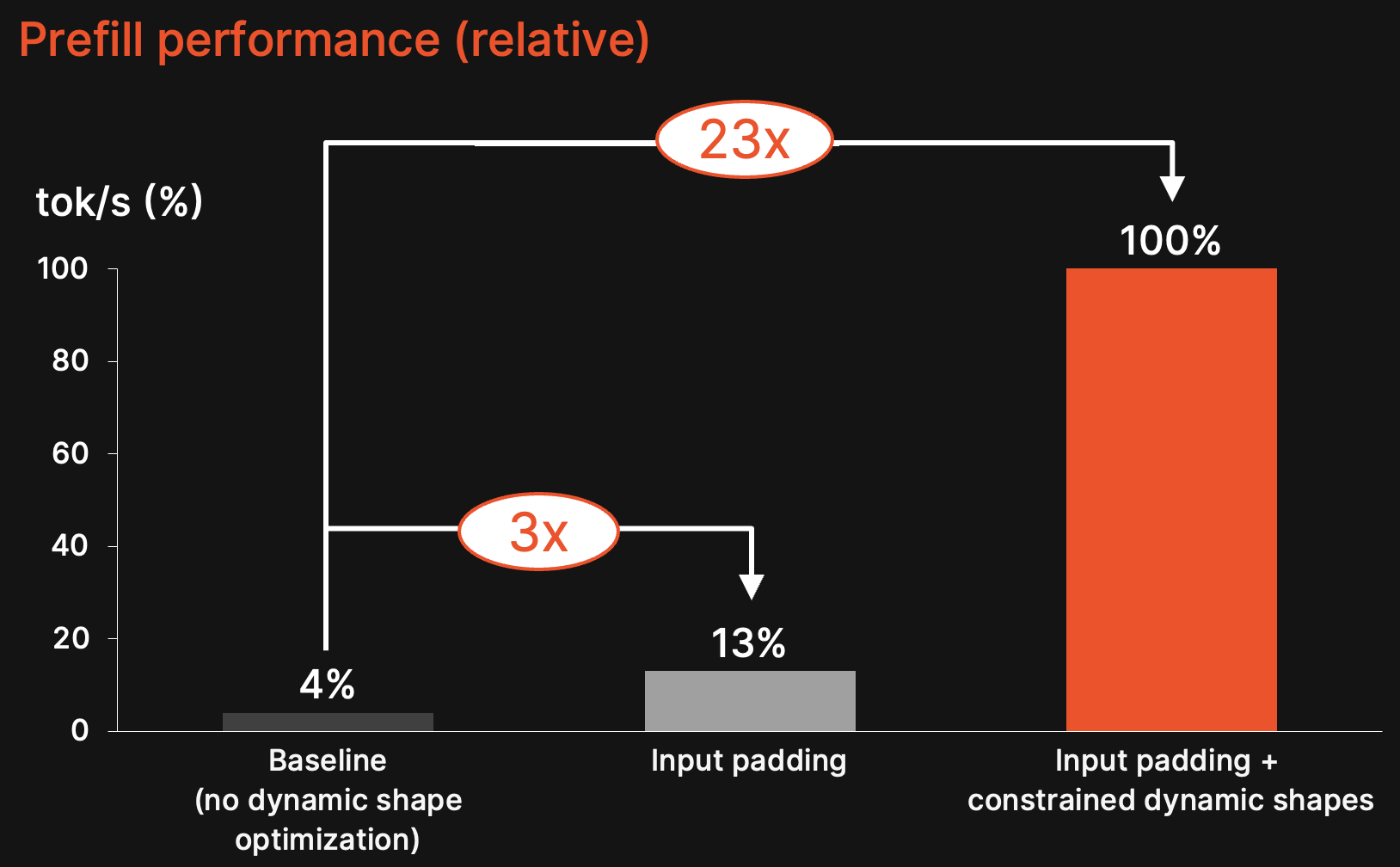
This strategy avoids extra kernel launches or memory transfers, generalizes across hardware targets such as GPUs and NPUs, and reliably improves overall prefill efficiency and confirms that constrained dynamic shape handling is a key enabler for practical, high-performance edge LLM inference. Importantly, padding is applied only once at the input prompt, and the resulting hardware-friendly shape guarantees are propagated through the entire network so that all downstream operations can take advantage of efficient fixed-size tensor instructions.
In the following video, our compiler engineer Thomas runs all three configurations on the same hardware showcasing our optimizations.
From compiler innovation to end-to-end edge LLM deployment
Beyond dynamic shape optimization, Roofline delivers a complete end-to-end edge LLM deployment stack that takes modern models from import through compilation and runtime execution to OpenAI-style API serving. By producing optimized artifacts with constrained dynamic dimensions and integrated KV-cache support, Roofline closes the gap between state-of-the-art models and practical on-device deployment.
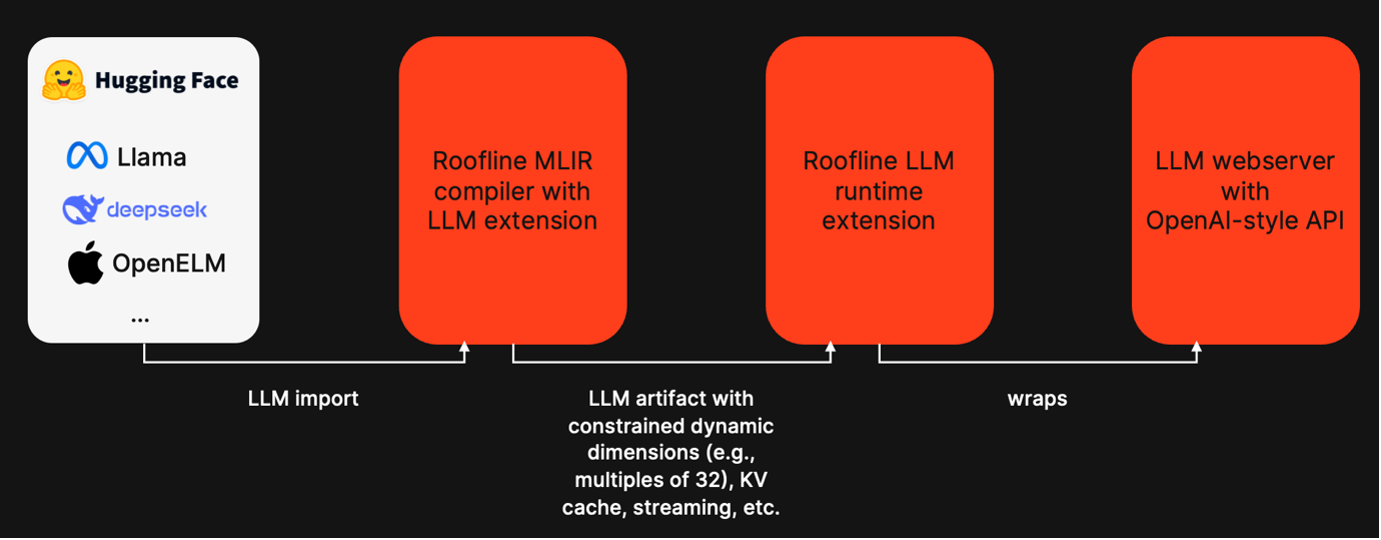
With these infrastructure advancements, Roofline lays the foundation for efficient GenAI deployment at the edge. Handling of dynamic shapes is a core pre-requisite for efficient LLM inference and will enable the next generation of disruptive use cases like agentic AI. Reach out if you want to explore deploying generative AI on your edge hardware and stay tuned for our next case study.

