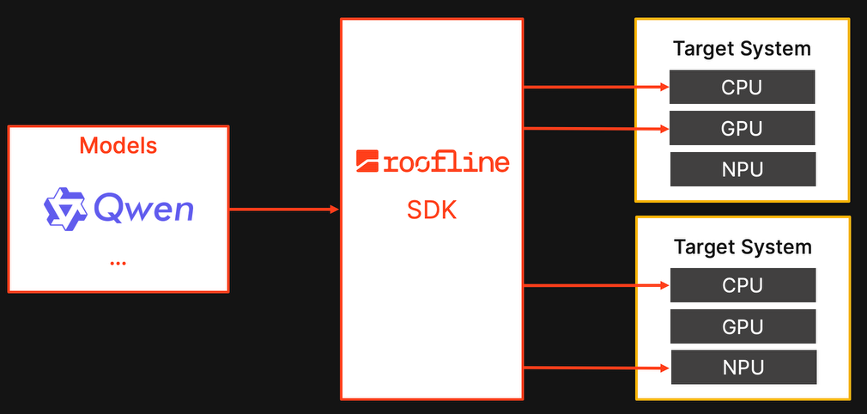
エッジSoC向け非同期ヘテロジニアス実行
このケース・スタディでは、Rooflineが最新のエッジ向けシステム・オン・チップ(SoC)において、いかにして非同期ヘテロジニアス実行を実現したかを紹介します。当社の技術は、SoC内のCPU、GPU、NPUのハードウェアを連携させ、AIモデル全体を効率的に実行します。これにより、エッジにおけるAI展開ソフトウェアに長年欠けていた重要な要素を補完し、最適なデバイス上でより大規模なモデルを効率的に実行することを可能にします。
急速に進化するエッジAIモデルにおいて、非同期ヘテロジニアス実行は不可欠
エッジAIは、以下の3つのトレンドに牽引され、急速に進化しています:
1. モデルは、エッジにおける厳格な電力およびレイテンシの制約に適合するよう小型化が進んでおり、機能をクラウドに委ねるのではなく、デバイス上で直接より多くの機能を実行できるようになっています。
2. エージェント型AIがエッジへと移行し、自律的で常時利用可能なアプリケーションを実現しています 。
3. エッジハードウェアはチップ上の異種混在型コンピューティングスタックへと進化しており、最新のSoCはCPU、GPU、NPUを、それぞれの強みを補完し合う形で統合しています。
これら3つのトレンドは、デプロイメント・ソフトウェア層の課題となっています。個々のデバイス上で最先端のモデルを動作させること自体が困難ですが、それらのモデルをデバイス間で効率的に分散させることはさらに困難です。
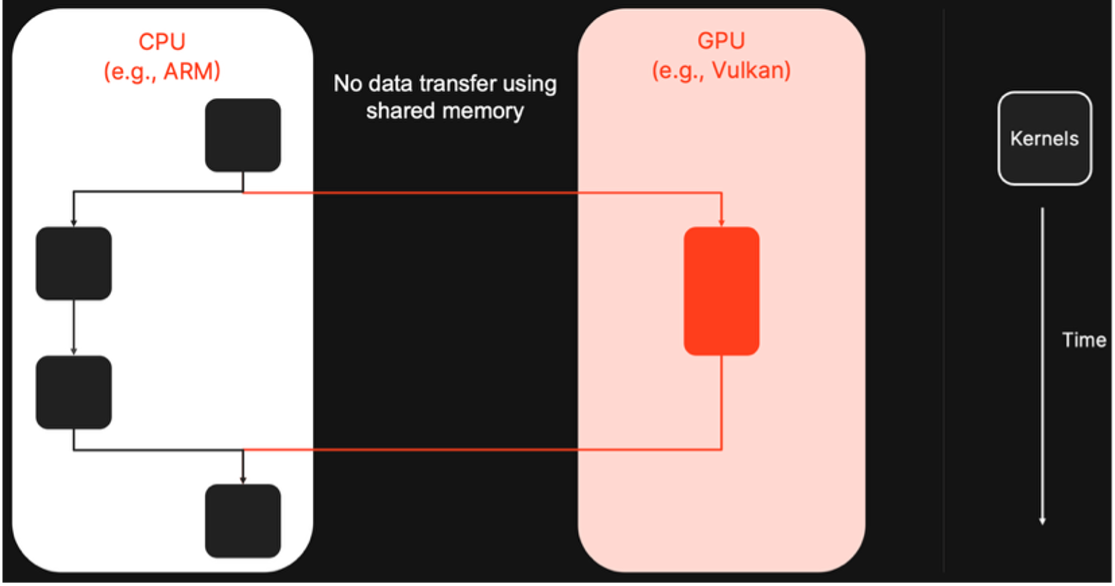
ここで欠けていた重要な要素が、「ヘテロジニアス非同期実行」です。これはモデルを分割し、各セグメントを最適なデバイス上で実行するとともに、デバイス間で演算能力とメモリをプールすることで、単一のデバイスでは処理できない、より大規模で高性能なモデルをサポートします。一般的なエッジAIデプロイメント・ソフトウェアでは、通常この機能を提供できません。ほとんどのデプロイメント・ソフトウェアは、ヘテロジニアス実行をサポートしていないか、あるいはデバイスが同期 して動作し、CPUがGPU/NPUの結果を待機する同期型の実行方式を採用してお おり、ハードウェア・リソースを浪費しています。
非同期のヘテロジニアス実行により、デバイス間の連携が並列に行われ、CPU/GPU/NPU上で処理が並行実行され、待機時間やハンドオフのオーバーヘッドを最小限に抑えます。このモードは、オンチップのすべての演算リソースを最大限に活用できます。さらに、分散処理によって大規模なモデルの実行を高速化し、CPU、GPU、NPUの演算能力を組み合わせた複雑なエージェント型パイプラインをサポートするため、エッジAIのさらなる発展において極めて重要です。
Rooflineは、多様なベンダやSoCに対してこれを実用化するための移植性の高いエンド・ツー・エンドのインフラを構築しており、これにより、高度なエッジAIがチップ全体の能力を一貫して活用できるようになります。
Roofline のMLIR + IREEインフラストラクチャにより非同期ヘテロジニアス実行を実現
Rooflineは、2つの具体的な成果を通じて、非同期ヘテロジニアス実行を実際に実現しました。
1. ポータブルな非同期クロス・デバイス実行に必要なインフラストラクチャをMLIRおよびIREEで構築し、コンパイラの主要部分をアップストリームに統合しました(例: PR20885, PR21005,PR21029)。
2. このインフラストラクチャを完全なエンド・ツー・エンドのフローに統合し、完成したモデルが実際のターゲット・システム間で非同期に実行できるようにしました。
移植性を実証するため、NXP、Apple、Qualcommの3種類の異なるエッジSoC上でこのスタックを動作させ、CPUとGPUでの非同期実行を行いました。これにより、ベンダーやデバイスを超えた移植性が実証されました。その仕組みは、以下の3つの技術に基づいています:
1. ハードウェア・アーキテクチャを意識したコンパイラを備えたCPU-GPU共有メモリ: デバイス間で共有メモリ空間を確立し、コンパイラがSoCのアーキテクチャに基づいてバッファ配置を計画できるようにします。これにより、デバイス間のコストのかかるコピーを回避し、デバイスのカーネル間でのゼロコピー・データ・ハンドオフを実現します。
2. 非同期境界を統合したモデル分割:コンパイラはモデルをデバイス固有のサブグラフに分割し、中間表現内に直接非同期ハンドオフ・ポイントと共有メモリ・インターフェースを作成します。各デバイスは、自らが最も効率的に実行できる演算を実行し、デバイス間のすべての遷移は明示的にスケジューリングおよび最適化されます。
3. ランタイムにおけるクロス・バックエンド同期:ランタイムは、バックエンド固有の同期プリミティブ(例:VulkanやCPU)を、統一された非同期調整レイヤへと統合します。これにより、デバイス間の並列実行が可能となり、デバイスに同期動作を強制することなく、データ依存関係が確実に遵守されます。
エンド・ツー・エンドのデモにより、移植性が高くアイドル時間が短いヘテロジニアス実行が実証されました
当社
上記の動画は、3つのプラットフォーム上でヘテロジニアス実行により動作するQwen3-0.6B / 1.7Bにおける当社の技術の実演を示しており、当社のスタックの移植性を強調しています。このデモでは、モデル固有のチューニングを行わないベースラインのシステム構成を使用しているため、再生速度は調整されており、パフォーマンス数値は伏せられています。その目的は、エンドツーエンドのヘテロジニアス実行を示すことであり、ベンチマークとして機能することではありません。
ポータブルなインフラストラクチャが、NPUおよび3デバイスによる実行の基盤を築く
本研究は、非同期のヘテロジニアス実行のためのポータブルなインフラストラクチャ層を提供し、ヘテロジニアスなエッジSoCを、実際のモデル展開においてその性能を最大限に活用できるシステムへと変貌させます。これにより、非同期のヘテロジニアス実行をベンダーを問わず実用的かつポータブルなものとし、エッジAIソフトウェアにおける重要な課題を解決します。このケーススタディではCPUとGPUを例に挙げていますが、同じインフラストラクチャはNPUにも適用可能です。NPUは通常、特定の演算サブセットのみを高速化するため、残りのワークロードはCPUやGPU上で効率的に実行可能です。異種実行により、これらの要素を1つのパイプラインに統合できる点が、本技術の重要な意義です。今後、NPUをスタックに統合し、3デバイス(CPU + GPU + NPU)による非同期実行へと拡張していく予定ですので、ご期待ください!

