Asynchronous Heterogeneous Execution for Edge SoCs
This case study shows how Roofline enabled asynchronous heterogeneous execution on modern edge System-on-Chips (SoCs). Our technology coordinates the SoCs’ CPU–GPU–NPU hardware for running full AI models efficiently. We unlock a long-missing piece in AI deployment software on the edge to run larger models more efficiently on the best suited device available.
Fast edge AI model evolution demands asynchronous heterogeneous execution
Edge AI is progressing at lightspeed, driven by three trends:
1. Models are shrinking to fit strict edge power and latency budgets, letting products run more functionality directly on-device instead of pushing features to the cloud.
2. Agentic AI is moving onto the edge, enabling autonomous, always-available applications.
3. Edge hardware has become a heterogeneous compute stack on a chip, modern SoCs combine CPUs, GPUs, and NPUs with complementary strengths.
These three trends raise the challenge for the deployment software layer. While enabling cutting-edge models on each device individually is hard, distributing them efficiently across devices is even harder.
The critical missing piece is heterogeneous asynchronous execution. It splits a model so each segment runs on the best-suited device and pools compute and memory across devices to support larger, more capable models than a single device could handle. Edge-AI deployment software typically cannot provide this capability. Most deployment software either doesn’t support heterogeneous execution or offers synchronous variants where devices run in lockstep and the CPU waits on GPU/NPU results, wasting hardware resources.
Asynchronous heterogeneous execution will coordinate devices in parallel so that work is run on CPU/GPU/NPU in parallel and with minimal waiting or handoff overhead. This mode is key for further edge-AI development because it fully utilizes all on-chip compute resources, enables faster execution of larger model through distribution, and supports complex agentic pipelines that rely on combined CPU, GPU, and NPU computing.
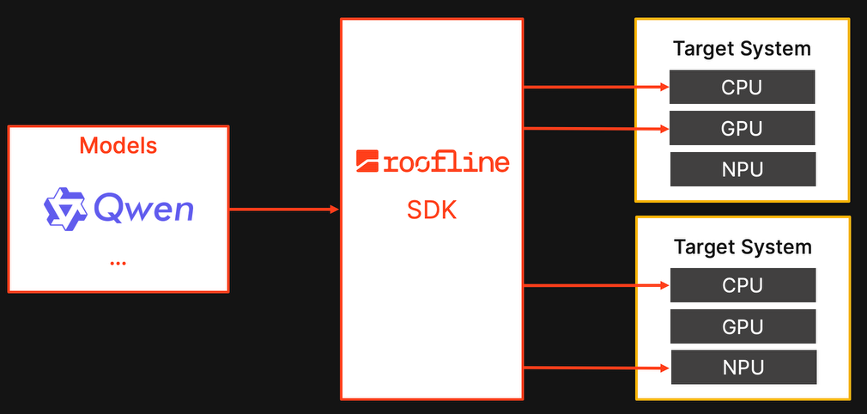
Roofline is building the portable, end-to-end infrastructure to make this practical across diverse vendors and SoCs so that advanced edge AI consistently benefits from the capabilities of the whole chip.
Roofline unlocks asynchronous heterogeneous execution with MLIR + IREE infrastructure
Roofline unlocks asynchronous heterogeneous execution in practice through two concrete achievements.
1. We built the required infrastructure in MLIR and IREE for portable asynchronous cross-device execution, and upstreamed core parts of the compiler (e.g., PR20885, PR21005, PR21029).
2. We integrated this infrastructure into full end-to-end flows so complete models can run asynchronously across real target systems.
To demonstrate portability, we brought the stack up on three heterogeneous edge SoCs (NXP, Apple, and Qualcomm) for asynchronous execution in CPU and GPU. This validates portability across vendors and devices. Under the hood, the capability rests on three pillars:
1. Shared CPU-GPU memory with hardware-architecture-aware compiler support: We establish a shared memory space across devices and let the compiler plan buffer placement based on the SoC’s architecture. This avoids costly copies between devices and enables zero-copy data handoff between device kernels.
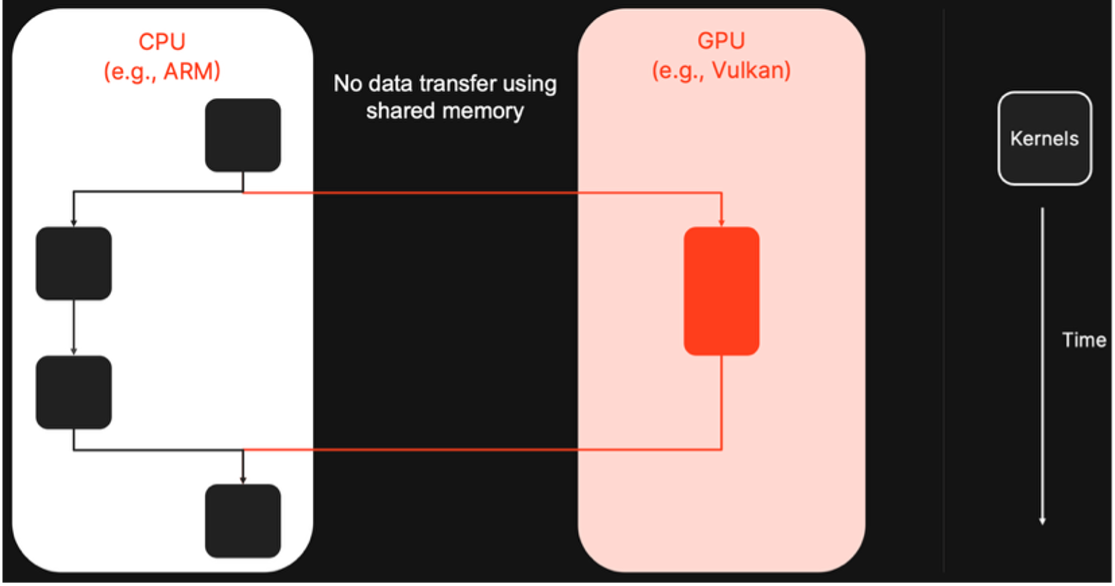
2. Model partitioning with integrated async boundaries: The compiler splits the model into device-specific subgraphs, creating async handoff points and shared-memory interfaces directly in the intermediate representations. Each device runs the ops it performs best, while all cross-device transitions are explicitly scheduled and optimized.
3. Cross-backend synchronization in the runtime: The runtime bridges backend-specific synchronization primitives (e.g., Vulkan and CPU) into a unified async coordination layer. This enables parallel execution across devices, ensuring that data dependencies are respected without forcing devices to run in lockstep.
End-to-end demos confirm portable, low-idle heterogeneous execution
We demonstrated end-to-end asynchronous heterogeneous model execution on three edge SoCs from relevant vendors (NXP, Apple, Qualcomm), with efficient cross-device handoff via our shared-memory and async runtime infrastructure. Across these systems, the runtime-compiler combination keeps workloads continuously overlapped, avoids unnecessary synchronization stalls and enables low-idle coordination between devices. This establishes a practical, portable path to deploy full models across heterogeneous SoCs with high utilization and low orchestration overhead.
The video above illustrates our technology in action for Qwen3-0.6B / 1.7B, running via heterogeneous execution on the three platforms, highlighting the portability of our stack. As this demo uses baseline system configurations without model-specific tuning, the playback speed is adjusted, and performance numbers are masked. Its purpose is to show end-to-end heterogeneous execution, not to serve as a benchmark.
Portable infrastructure sets the stage for NPU and three-device execution
This work delivers a portable infrastructure layer for asynchronous heterogeneous execution, turning heterogeneous edge SoCs into fully utilized systems for real model deployments. It closes a key gap in edge-AI software by making asynchronous heterogeneous execution practical and portable across vendors. While this case study showcases CPU and GPU, the same infrastructure carries over to NPUs. This technology is crucial because NPUs typically accelerate only a specific subset of operations and the remaining workloads can run efficiently on CPU and GPU, with heterogeneous execution tying these pieces into one pipeline. Stay tuned as we bring NPU integration into the stack and expand to three-device asynchronous execution (CPU + GPU + NPU)!

