Roofline and NXP enable next-generation software support for LLMs on eIQ Neutron NPU
Advanced AI models are rapidly moving to edge devices, driving demand for on-device compute that CPUs and GPUs alone cannot satisfy. To meet this demand, dedicated AI accelerators, or NPUs, are being embedded into edge SoCs.
In collaboration with NXP® Semiconductors, we built on Roofline’s scalable MLIR and IREE compiler infrastructure to extend our heterogeneous execution stack to NPUs. Starting with LLM enablement for NXP’s eIQ® Neutron NPU on the i.MX 95 applications processor, this case study showcases three key advantages of the software enablement: 1) Unlocking broad model coverage, 2) overcoming accelerator memory limitations for models above 2GB, and 3) delivering clear performance gains of up to 3.2x in LLM prefill performance over CPU-only execution.
Software velocity unlocks the full potential of edge AI hardware innovation
In edge AI, new models and new use cases are emerging faster than ever, while semiconductor companies are shipping processors with increasingly capable NPUs. However, hardware innovation alone does not translate into real-world adoption. The decisive factor is the connection between applications and silicon. This connection is defined by software velocity, which rests on two key levers:
1. Day-0 support: New models compile and run on target hardware by default. While performance might not yet be fully optimized for each and every model, this unlocks immediate evaluation, prototyping and product development.
2. Steep optimization curve: Targeted compiler improvements drive performance from functional to production-ready within days or weeks, not months of manual kernel engineering.
This software enablement allows application and product developers to focus on what truly differentiates them: Refining and iterating use cases, advancing features, and accelerating time-to-market.
Roofline's compiler infrastructure and NXP's hardware-specific expertise combine to enable Day-0 NPU support
Achieving software velocity for NPUs requires two complementary capabilities: A flexible and efficient AI compiler infrastructure, combined with deep hardware-specific optimization expertise.
Building on MLIR and IREE, Roofline brings software infrastructure that cleanly separates hardware-agnostic and hardware-specific concerns. Standing on the shoulders of this powerful ecosystem, the infrastructure allows seamless model importing across frameworks, applies generic optimizations, and brings target agnostic features like heterogeneous execution.
On the hardware-specific side, NXP brings deep expertise in software optimization for their own silicon. Backends are purpose-built and continuously optimized for their specific architecture, ensuring that operations run at maximum efficiency.
This separation of concerns enables a scalable software stack for Day-0 support across a diverse hardware portfolio: Targeting new devices requires the integration of a new hardware-specific backend but not re-writing the whole stack from top to bottom.
As a first step in the Roofline x NXP collaboration, we applied this infrastructure to the i.MX 95 SoC, targeting the eIQ Neutron NPU as the first accelerator backend.
NXP's eIQ Neutron NPU excels at MAC-heavy AI workloads: A natural fit for vision networks, challenging for LLM enablement
NXP has been greatly expanding its AI capabilities. A key cornerstone in this expanded Edge AI enablement is the eIQ® Neutron Neural Processing Unit (NPU), a highly scalable accelerator core architecture. In the NXP i.MX 95 SoC, eIQ Neutron NPU is implemented as a 8 eTOPS accelerator with a dedicated 2GB memory space. eIQ Neutron NPU is purpose-built for executing multiply-accumulate (MAC) operations at a massive scale. Matrix multiplications, convolutions, and dot products are all reduced to MACs, and by packing thousands of MAC units into a near-memory-compute architecture with tightly coupled local memory, Neutron delivers high compute utilization and energy efficiency. On standardized vision benchmarks, this design has already proven its capabilities: NXP reports an average 1.8x speedup over a competing embedded NPU at equal TOPS and memory resources(1).
While this architecture is a natural fit for convolutions and matrix-heavy vision workloads, enabling LLM inference introduces additional challenges. NXP’s eIQ Neutron NPU exclusively performs integer arithmetic, meaning only quantized operations can run on the accelerator. LLMs combine MAC-heavy matrix multiplications that map well to Neutron with operations that require floating-point arithmetic, even in fully quantized models. In addition, powerful edge LLMs can exceed the NXP eIQ Neutron NPU’s 2GB local memory space.
Unlocking the NXP eIQ Neutron NPU for LLMs therefore requires heterogeneous execution: Offloading MAC-intensive matrix multiplications to the NPU while executing remaining operations on the CPU, coordinated through efficient scheduling and memory management. This workload partitioning enables the accelerator to operate at high efficiency while preserving full model functionality.
NXP and Roofline join forces to enhance software support for the Neutron NPU
Roofline and NXP jointly enabled compiled LLM inference that runs heterogeneously across the NXP eIQ Neutron NPU and CPU on NXP’s i.MX 95 SoC. This was achieved through three concrete contributions:
1. Backend Integration: Roofline and NXP jointly integrated the Neutron backend into Roofline's compiler infrastructure, build on MLIR and IREE. The compiler automatically identifies matrix multiplications in the model and routes them to Neutron, while all remaining operations compile for the CPU.
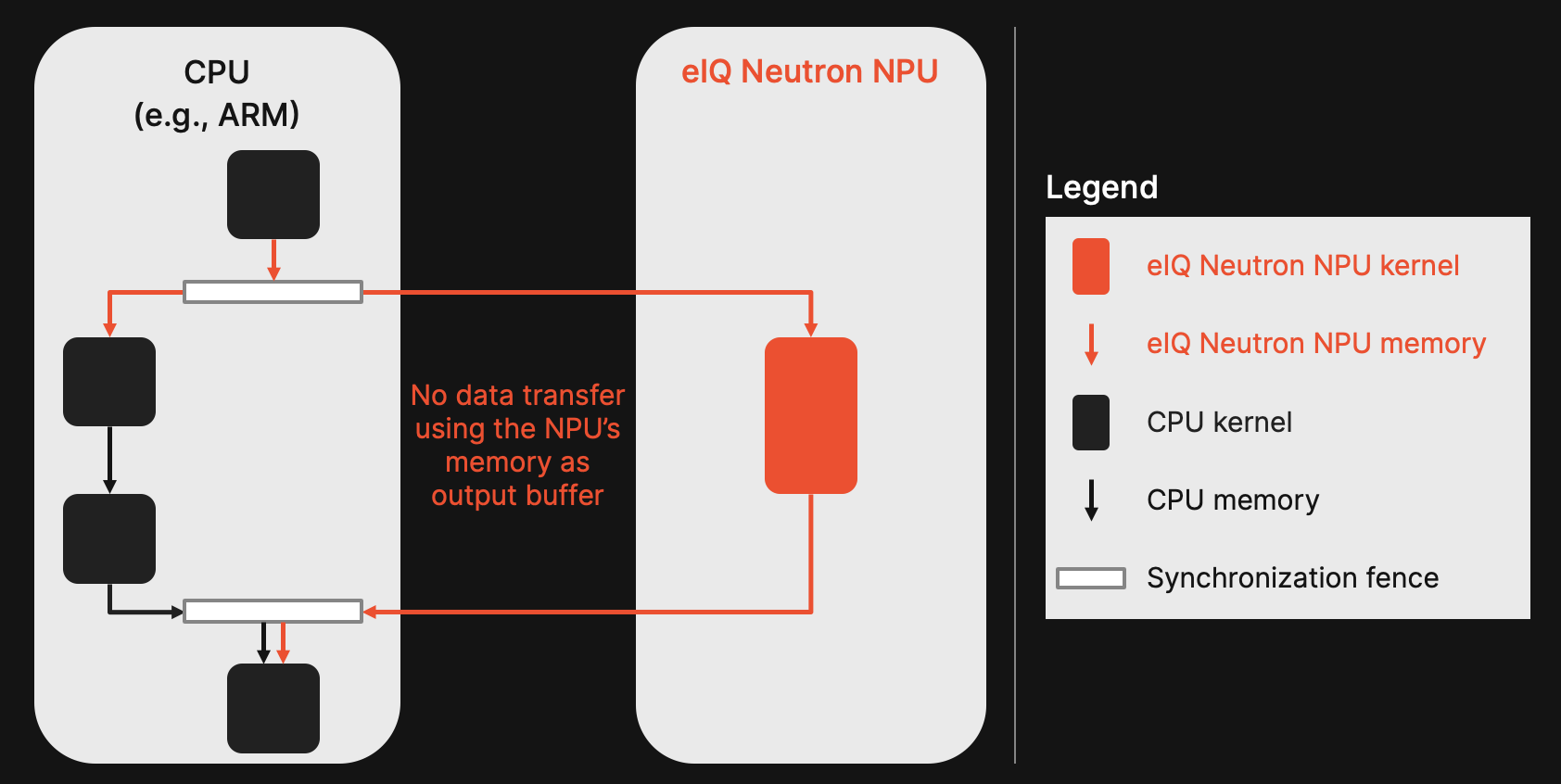
2. Asynchronous heterogenous execution: Following our previous case study on heterogenous execution and Figure 1, we have enabled asynchronous execution between the CPU and NPU. Instead of blocking calls that lead to idle times, the execution gets coordinated through lightweight synchronization fences. This allows each device to run the operations it performs best with minimal idle time.
3. Shared NPU memory: Neutron has shared memory space that is accessible to both the CPU and NPU. This allows both processing unit types to read from and write to the same memory. We leveraged this to minimize data transfer overhead between devices by allocating only the required input and output buffers in the NXP eIQ Neutron NPU's memory space. The CPU writes results of preceding operations directly into the NPU's input buffers and reads inputs for subsequent operations directly from the NPU's output buffers. This eliminates redundant copies and enables deployment of models exceeding the 2GB memory limit since only active I/O buffers reside on the NPU.
Through seamless asynchronous execution we are now able to run modern transformer-based LLMs jointly on CPU + NPU with Qwen3-1.7B as an example in the following video.
Clear advantages for LLM deployment on NXP eIQ Neutron NPU
The joint Roofline and NXP enablement of NXP’s eIQ Neutron NPU delivers three key results, each with direct practical implications for developers building on NXP hardware:
1. Fully compiled LLM enablement for NXP’s eIQ Neutron NPU: Starting from the initial enablement shown in the video above, Roofline and NXP expanded software support to virtually any 8-bit quantized LLM within just a few weeks, validated on a joint model zoo of 10+ LLMs from ONNX and PyTorch. Matmul offloading at the compiler level works for any LLM architecture, showcasing the scalability only provided by a truly compiler-based stack. This is the direct payoff of the separation of concerns: New models compile and run on Neutron without model-specific engineering.
2. Support for larger models: The shared NPU memory and zero-copy approach enables models that exceed the NPU’s 2GB memory, such as Qwen3-1.7B (slightly above 2GB) and Gemma-2-2b-it (~3.5GB).
3. Clear performance gains: Across all validated models, offloading matmuls to Neutron delivers consistent speed-ups during the LLM prefill phase. Figure 2 outlines benchmarks for six models of various sizes. The speed-up translates into up to 1.9x higher performance compared to a 6-core CPU baseline utilizing all available cores of the i.MX 95 SoC.

These results translate into three practical implications for developers building on NXP hardware:
1. Accelerated time-to-market through Day-0 LLM support on NXP’s eIQ Neutron NPU.
2. New use cases unlocked by deploying larger models that were previously out of reach.
3. Leveraging performance benefits to either speed up inference time or free compute resources for other workloads running on the same SoC. As shown in Figure 3, we see gains of up to 3.2x for NPU + CPU when comparing versus a single CPU core.

From first LLM enablement to full SoC utilization
This case study demonstrates how scalable compiler infrastructure unlocks software velocity for NPUs-based edge SoCs. Day-0 model support and steep optimization curves enable product and application developers on NXP hardware to focus on what matters most: Building applications, user experiences, and product differentiation that set them apart.
Next, we are extending the NXP eIQ Neutron NPU enablement from prefill to the decode phase of LLMs to ensure efficient SoC utilization during token generation. We will also expand the NXP eIQ Neutron NPU offloading capabilities to further operator types, unlocking performance gains also for less matmul-heavy models like conventional CNNs. The objective: ensure any AI model for any given use case can run across the entire NXP i.MX 95 SoC, making optimal use of the CPU, GPU, and NPU.
CITATIONS
(1) Bamberg, Lennart, et al. "eIQ Neutron: Redefining edge-AI inference with integrated npu and compiler innovations." arXiv preprint arXiv:2509.14388 (2025)

